
The Unicode Consortium, a non-Governmental body with headquarters in the U.S.A with Governmental agencies of many countries also as members, have standardised and maintains a Universal Character Set (UCS), i.e. a standard that defines, in one place, all the characters needed for writing the majority of living languages in use on computers. It aims to be, and to a large extent already is, a superset of all other character sets that have been encoded. Unicode (as the UCS is commonly referred to) can access over a million characters of which about 100,000 have already been defined. These include characters for all the world’s main languages along with a selection of symbols for various purposes.
REASONS OF DISSENSIONS AMONG THE ASSAMESE:
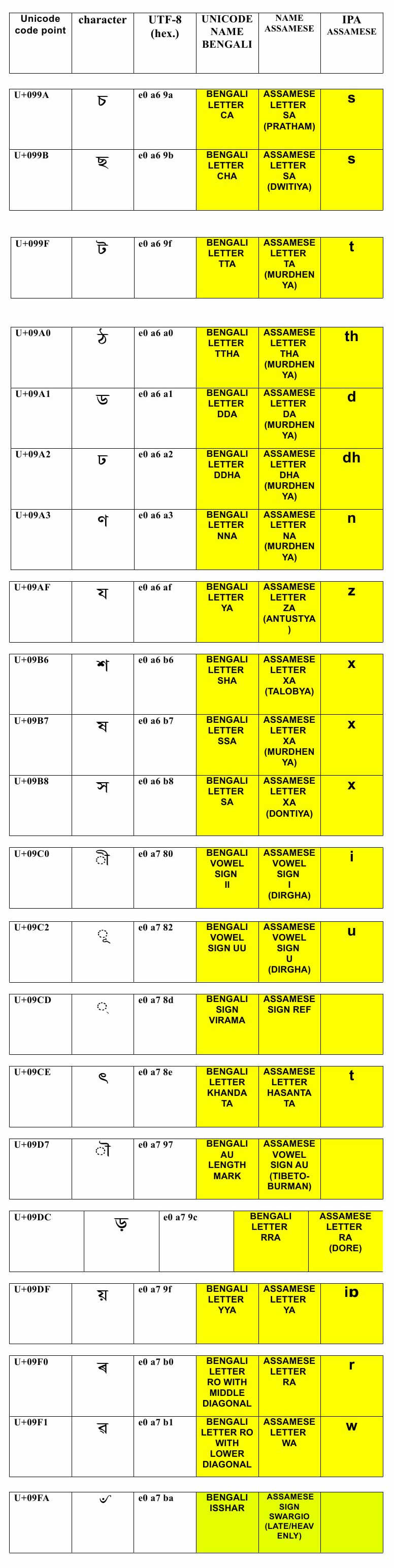
1. Non-representation/misrepresentation of the Assamese writing system in the Unicode Standard because the Unicode Consortium and also the Government of India thinks that the current Bengali Code chart will serve the purpose of using the Assamese language in computers.
2. The script is named as Bengali and all character descriptors in the Unicode Code Chart named as per the Bengali nomenclature and Assamese are forced to use it, neither the Government of India and the Unicode Consortium is willing to do anything positive on it. Both take it as a political issue and cite multiple technical difficulties in solving it, and try to convince the complainants that nothing is wrong with it.
3. But the fact remains that the Assamese alphabet “ৰ” (Ro) is being described as Bengali letter “র”(Ro) with middle diagonal, in the Bengali chart of the Unicode Standard.
4. Assamese alphabet “ৱ” (Wobo) described as Bengali letter “র”(Ro) with lower diagonal, in the Bengali chart of the Unicode Standard.
5. Thirteen other Assamese alphabets similarly misrepresented in the Bengali chart of the Unicode Standard.
6. Assamese alphabet “ক্ষ” (Khya) is not represented at all in the Bengali Code Chart of the Unicode.
7. This results in gross Collation Error which occurs when sorting softwares are run in Assamese as because “ৰ” (Ro) and “ৱ” (Wobo) are not in proper place and “ক্ষ” (Khya) is not represented at all in the Bengali Code Chart of the Unicode Standard.
SOLUTIONS UNDER CONSIDERATON :
1. RENAMING OF THE SCRIPT AND ALTERNATIVE NOMENCLATURE OF THE CHARACTER DESCRIPTORS
This is stated in the beginning because, the Government of India seems more interested in solving it that way. Renaming of the current Bengali script in the Unicode Standard with a name acceptable to all has been proposed by many. The problem with the renaming solution is there, both in the Bengali and Assamese side and most important a technical problem is associated with it.
A. Will the Bengali community agree to it, considering that the present Bengali code chart is serving their purpose quite well. The Bengali community is there in two sovereign countries India and Bangladesh.
B. The major problem lies on the Assamese side, will the renaming be limited to the renaming of the name of the Script and Code chart only or will it include the misrepresented character descriptors’ nomenclature also. For example the following Assamese characters have Bengali descriptors, different from how they would have been described in Assamese.
Supposing renaming is taken up as the best solution for solving the controversy then the whole current Bengali Code Chart of the Unicode Standard will have to have alternative nomenclature beginning with the title of the script like ASSAMESE AND BENGALI and the individual characters will also have alternative character descriptors like this :
U+09B8 “স” e0 a6 b8 = BENGALI LETTER SA / ASSAMESE LETTER XA (DONTIYA)
U+09AF “য” e0 a6 af = BENGALI LETTER YA / ASSAMESE LETTER ZA (ANTUSTYA)
If such an alteration is possible and every character is given both the Assamese and Bengali descriptors and the script renamed as per an acceptable name and the displaced and missing Assamese characters “ৰ” (Ro) and “ৱ” (Wobo) and “ক্ষ” (Khya) put in proper place in the chart, for proper collation the problem may be solved.
But as per the basic principle of a Unique Code, one particular entity can have one identifier, in this case around fifteen characters will have one identifier for two entities.
If Unicode Consortium or the Indian Government thinks that this basic principle of Unique Codification can be violated then the matter may be acceptable to the Assamese and Bengali alike.
2. SEPARATE SLOT/RANGE FOR THE ASSAMESE SCRIPT
If renaming in the way described above is not possible, then allocation of a separate slot/range for the Assamese Script remains the only solution. Which is perhaps easier for the Unicode Consortium to do. Government of Assam has also moved the Government of India seeking a separate slot/range for the Assamese script. Allocation of a separate slot/range for the Assamese Script will mean Unicode Consortium allowing and accepting duplication of characters. The Unicode Consortium has already allowed and accepted not only duplication but in case of some of the characters triplication of characters in the three major European writing systems viz. Cyrillic, Greek and Latin. Consequently in the Unicode Standard has more than the following number of duplicate characters :
a=2, A=3, B=3, c=2, C=2, e=2, E=3, H=3, i=2, I=3, j=2, J=2, K=2, M=3, N=2, o=2, O=3, p=2, P=3, s=2, S=2, T=2, x=2, X=3, y=2, Y=2 and Z=2
Here only there are a total of 63 (sixty three characters) duplicated between the three major European writing systems the Cyrillic, Greek and Latin, the actual number is more than this.
Number wise duplication of characters will be perhaps much less than this, if Bengali and Assamese scripts are duplicated and allocated separate slots/ range for themselves.
CONCLUSION:
The solution therefore lies in duplicity. In the first option there is going to be duplicity of the Unique Codes meaning single code for two entities and in the second option there is going to be duplicity of characters meaning two characters of the same appearance. The Unicode Consortium and the Government of India has to choose between the two. Duplicity of characters is already there in the Unicode Standard but whether duplicity of Unique Codes are there, or whether it is acceptable to the experts, whether it is justified, it is not known, because duplicity itself means loss of uniqueness of any Unique Code.
Dr Satyakam Phukan is a General Surgeon by profession and he can be reached at sphukan2009@yahoo.in.



So what does it matter if I can type Ro or Wobo in Assamese or in Bengali or if it is not a pet kota Ro what does it matter if I consider that Ro and Wobo does not exist at all what does it matter??????
The article has explained the possibilities and problems to declare Assamese script as an independent script. The article is based on realities about Assamese and Bengali script. The article will help the Unicode consortium to find out a proper solution, if they trust on the content of the article.
I would like to refer here the seminal work of language scientist Dr. Debi Prasanna Pattanayak’s “ A Controlled Historical Reconstruction of Oriya, Assamese, Bengali and Hindi” , particularly page 63 where substantive evidence has been put forward why Assamese is older than the rest. Moreover, Assamese rock writings discovered thus far and the Carya Versification written in Pakrit by Buddhist scholars of Kamrup cannot be other than original Assamese of the period.[ But, hijacked by Bengali linguist].
Therefore, why our linguists and the guardian organisation of the language cannot take up the issue to prove the originality of Assamese and win the argument with Unicode and establish that Assamese is the original independent script system albeit influenced by Sanskrit at a later time?
Thanks for your comment Dr Mukul Hazarika dangoria and a special thanks for enlightening about Devi Prasanna Pattanayak’s book. I did not know of this important information before.
I have dealt with in details on the subject of Assamese and Unicode in my report of the same name, it has been sent to the concerned parties that includes the Unicode Consortium (on the 3rd of October 2011) and the Governments and their agencies. It is actually a comprehensive report on the issue from my side. Interested readers can mail me for the report.
The report is in a pdf file.
Dr Satyakam Phukan
Author of this article
I am from Lakhimpur and I study in class IX. I read what you wrote, I really liked the idea. I have read about this on a few newspapers, other places on the internet etc before too, but this one is the most detailed. I too want the Assamese script to be added to the Unicode standard, but I have a question. There are many websites that have a lot of content in Assamese, in Bengali script of Unicode (almost all the sites). For example, there are 3000+ articles in Assamese Wikipedia, in Bengali Script. If new (Assamese) characters are added to Unicode, what should the sites do with their content (in Bengali script)? It will be a big problem to change the characters! Or is there any technical solution to it??
Please reply.